- 0) 前提
- 1) 基本セットアップ(WSL / Ubuntu)
- 2) uv をインストール(依存を自動解決する実行ツール)
- 3) リポジトリ取得とブランチ切替
- 4) uv で依存関係をそろえる(Python 3.10 を強制)
- 5)音声認識モデルの導入(推奨構成)
- ローカルにLLMをインストールしてAITuberを動かしたい方(ハイスペックPC推奨(GPU搭載機など)) ※OPENAI API / Gemini API を使用する方はスキップしてください。
- 6-1) Ollama を導入(ローカルLLM)
- 6-2) conf.yaml の最小編集(Ollama接続 & 日本語TTS)
- ChatGPT(OPEN API LLM / Gemini )など、LLMを使用して AItuberを動作させたい方(ロースペックPCでも快適に動作するので推奨)
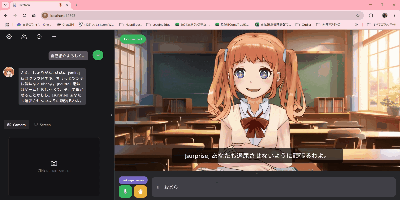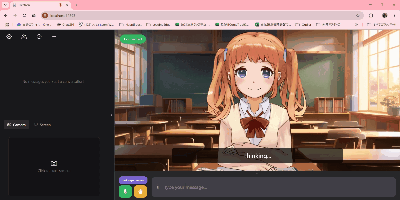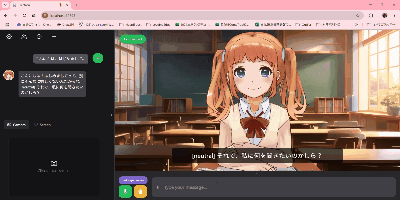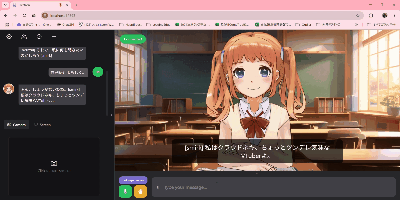
- 7)AITuberサーバ起動
0) 前提
Windows 11 + WSL2(Ubuntu 22.04 以上)
VS Code(WSL拡張)
WSLのインストールとVSCodeのインストールは
こちらの記事で紹介しましたのでご参照ください。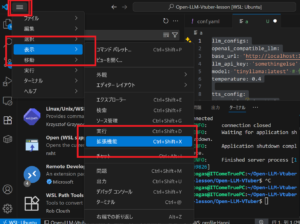

コメント